
Our Blog
Insights and updates on emerging technology trends.
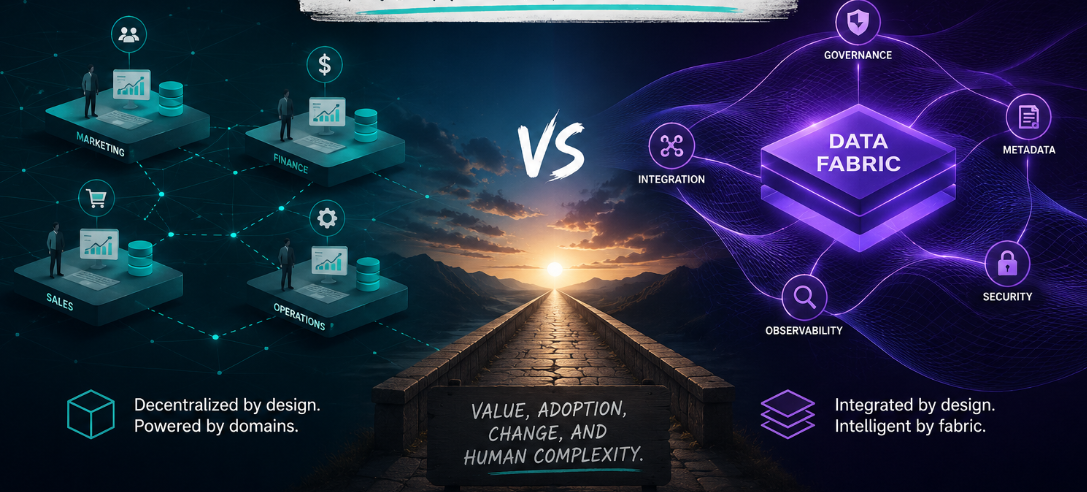
Data Mesh vs Data Fabric: The Debate Is Over. The Hard Part Isn't.
Gartner's 2025 Data & Analytics Summit ran a session titled "R.I.P. Data Fabric vs. Mesh Debate." It was a formal acknowledgement of something practitioners had already figured out in production: these two architectures aren't competitors. They never really were.
May 2, 2026
Read More →📝
Agentic RPA: When Bots Stop Following Instructions and Start Making Decisions
Traditional RPA has a reliability problem that the industry talked around for years. When it worked, it worked beautifully — fast, tireless, perfectly consistent. When it broke, it broke in the most frustrating way possible: silently, on an exception nobody had anticipated, often discovered only when a queue had been filling for hours and someone finally noticed.
May 2, 2026
Read More →
Reasoning Models Are Not Just Smarter LLMs. They're a Different Inference Paradigm.
There's a moment in most ML engineers' lives when they first watch a reasoning model work through a hard problem — not generating an answer, but visibly thinking toward one, revising, catching its own mistakes, trying a different angle. The output quality jump is obvious. What's less obvious is what that jump costs, and whether it's worth it for your specific use case.
May 2, 2026
Read More →
The AI-Augmented Data Engineer: What the Role Actually Looks Like in 2026
Somewhere between "AI will replace data engineers" and "AI is just autocomplete" sits a more accurate and more interesting reality. The data engineer's job in 2026 hasn't disappeared. It's been compressed at the bottom and expanded at the top — and the engineers who understand that distinction are pulling significantly ahead of those who don't.
May 2, 2026
Read More →
Correlation Still Isn't Causation. In 2026, Employers Are Finally Asking for the Difference.
For years, the standard data scientist job posting asked for Python, ML frameworks, and some vague mention of "statistical knowledge." Causal inference barely appeared. A/B testing was listed occasionally, usually as a nice-to-have buried below fifteen other requirements.
April 27, 2026
Read More →

SLM vs LLM - Not Every Task Deserves a Frontier Model. Here's How to Choose.
For a long time, the default answer to "which model should we use?" was the biggest one available. GPT-4 for everything. Frontier model as the baseline, then work out the cost later. It made sense when the tooling was immature and teams were still figuring out what worked — you don't optimise what you haven't validated yet.
April 21, 2026
Read More →
Your Pipeline Works. Your Data Doesn't. That's a Data Contracts Problem.
The failure mode most data teams don't see coming looks like this: a pipeline runs cleanly, all green, no errors. A dashboard updates. An executive makes a decision based on it. The decision is wrong, because the revenue figures were stale by 36 hours due to an upstream schema change nobody documented, and the pipeline had no idea anything was different.
April 20, 2026
Read More →
MLOps in 2026: The Consolidation Was Necessary. Here's What Survived.
There was a period, roughly 2021 to 2023, where the MLOps tooling landscape felt like a startup generator. New experiment tracking tools, new model registries, new monitoring platforms, new feature stores — each solving one narrow slice of the ML lifecycle, each requiring its own login, its own configuration, its own learning curve. Teams assembled stacks of twelve, fifteen, sometimes more tools, most of which overlapped, several of which nobody could explain why they'd been added.
April 16, 2026
Read More →
RPA Isn't Dead. It Just Got a Much More Ambitious Job Description.
Every year for the past three years, someone has published a piece declaring RPA dead. And every year the market grows. The global RPA market was valued at $28 billion in 2025 and is tracking toward $247 billion by 2035. That's not a dying technology — that's a technology that kept getting folded into something bigger until the original label started feeling inadequate. What's actually happening is more interesting than a death or a rebirth. RPA is becoming the execution layer of a much broader system. And understanding where it fits in that system is what separates automation programs that scale from automation programs that stall.
April 14, 2026
Read More →

Batch Is Not Enough Anymore. Here's What the Real-Time Stack Actually Looks Like.
There's a moment most data engineers recognize. You've built a solid batch pipeline — clean, tested, running on schedule every night. Then someone from the fraud team asks why the model is missing transactions that happened two hours ago. Or the product team wants personalization that reflects what a user did five minutes ago, not yesterday. Suddenly your nightly job feels like infrastructure from a different era.
April 9, 2026
Read More →
Prompt Engineering Is a Subset. Context Engineering Is the Job.
There's a quiet skill gap opening up between data scientists who are building LLM applications that work reliably in production and those who aren't. It doesn't show up in job descriptions yet. Most people aren't teaching it in courses. But if you talk to the engineers actually shipping AI systems that hold up under real workloads, they all converge on the same thing: the quality of your prompts matters far less than the quality of the context surrounding them.
April 5, 2026
Read More →
Dashboards Aren't Dead. But They're No Longer the Point.
Dashboards will be with us for a long time. They're not disappearing. But something genuinely important has shifted in how analytics teams are spending their time, and if you're still treating the dashboard as the end product of your BI work, you're building for a model of consumption that's quietly becoming the secondary one. The shift is this: people are increasingly asking questions instead of reading reports.
April 2, 2026
Read More →
From Naive RAG to Agentic RAG: What the Upgrade Actually Looks Like
One engineering team rebuilt their RAG pipeline from scratch after it was answering 40% of queries confidently and completely wrong. Not vague. Not almost-right. Wrong in the way that gets legal teams involved. The fix wasn't a bigger model or better embeddings. It was rethinking the retrieval architecture entirely — and accuracy jumped from 60% to 94%. That story captures where most teams are right now. They built a RAG system. It kind of works. And they're not sure why it keeps failing on the queries that actually matter.
April 1, 2026
Read More →
Iceberg, Delta Lake, Hudi: Stop Asking Which Is Best and Start Asking Which Is Right for You
The table format debate has been running for years now, and somehow people are still writing articles that end with "it depends." That's true — but also not very useful. Let me try to be more direct about it. All three — Apache Iceberg, Delta Lake, and Apache Hudi — solve the same core problem: raw data lakes are messy. Files accumulate without structure, concurrent writes create chaos, and querying historical states borders on painful. Open table formats bring ACID guarantees, schema evolution, and time travel on top of cheap object storage. That's the common ground. The differences are where it gets interesting.
March 30, 2026
Read More →
Agentic Analytics: What Multi-Agent ML Systems Actually Mean for Data Scientists in 2026
There's a version of this article that opens with a breathless claim about AI changing everything. This isn't that article. What's actually happening in machine learning right now is more specific — and honestly more interesting — than any sweeping statement would suggest. The shift isn't that AI is getting smarter. It's that the architecture of how we deploy intelligence has fundamentally changed. We've gone from building models to building systems of models, and most data scientists I know are only halfway through processing what that means for their day-to-day work. So let's talk about it properly.
March 29, 2026
Read More →
The Q1 2026 Tech Pulse: From Predictive Tools to Autonomous Partners
If 2025 was the year of "the pilot," Q1 2026 has officially become the year of The Agentic Pivot. The first three months of 2026 have shifted the industry’s focus away from singular chatbots toward interconnected, autonomous ecosystems. At Intellibridge, we’ve watched this transition closely—not just as observers, but as architects of the systems that bridge the gap between legacy data and this new frontier of intelligence. The highlights of this quarter aren’t just about faster chips or larger parameters; they are about utility, reliability, and the decentralization of intelligence. From the release of Gemini 3.1 Pro to the mainstreaming of Physics-Informed Machine Learning (PIML), the tech stack of 2026 is smarter, leaner, and more grounded in the physical world than ever before.
March 9, 2026
Read More →
A Look Back at the Tech Buzz That Defined 2025 (and What It Means Going Forward)
If 2025 taught us anything, it’s this: Technology is no longer “coming soon.” It has already arrived—and it’s changing how work actually gets done. From AI tools quietly entering everyday workflows to automation becoming a default expectation rather than a bonus, 2025 was less about hype and more about real adoption. As we step into 2026, this blog marks the beginning of IntelliBridge’s space for practical insights, grounded opinions, and real-world tech conversations. No buzzword overload. No theory dumps. Just what actually mattered—and what’s likely to matter next.
January 14, 2026
Read More →Showing 20 blog posts